
Bạn từng tự hỏi khi bạn nhập từ khóa vào công cụ tìm kiếm, làm thế nào những kết quả xuất hiện một cách nhanh chóng và chính xác trên màn hình của bạn? Đằng sau bức màn nhỏ đó, có một quá trình quan trọng được gọi là "crawl," và chúng ta sẽ khám phá "crawl là gì". Cùng nhau tìm hiểu về cách chương trình Web Crawler và Web Spider hoạt động, và tại sao chúng lại đóng một vai trò quan trọng trong việc biến các trang web thành những nguồn thông tin dễ dàng truy cập.
Trong thế giới web, "crawl" giống như việc "cào" thông tin từ các trang web. Điều này thường được thực hiện bởi những chương trình máy tính gọi là "web crawlers" hoặc "web spiders." Khi chúng "cào" một trang web, chúng đơn giản là đi qua từng trang, nhặt thông tin và tiếp tục làm điều này trên những trang khác.
Quá trình "crawl" là cực kỳ quan trọng để xây dựng một loại danh sách từ trang web, giúp công cụ tìm kiếm hiểu rõ về nội dung của chúng. Tưởng tượng như bạn đang "cào" thông tin từ một đống sách để tạo ra một danh sách thuận tiện để tìm kiếm. Điều này giúp công cụ tìm kiếm cung cấp kết quả tìm kiếm chính xác và nhanh chóng khi bạn đang tìm kiếm trên internet.
Trong ngữ cảnh của web crawler, "crawl" đề cập đến quá trình tự động tìm kiếm và thu thập thông tin từ các trang web trên internet. Các chương trình máy tính hoặc bot được thiết kế để thực hiện quá trình này được gọi là "web crawlers" hoặc "web spiders". Khi một web crawler "crawls" một trang web, nó theo dõi các liên kết, thu thập dữ liệu từ trang web đó, và sau đó tiếp tục đến các trang web liên kết khác để lặp lại quá trình này. Quá trình "crawl" là cơ sở để xây dựng chỉ mục cho các công cụ tìm kiếm và đóng một vai trò quan trọng trong việc cung cấp thông tin tổng hợp và dễ tìm kiếm trên internet.
Một web crawler, hay còn gọi là crawler hoặc web spider, là một chương trình máy tính được sử dụng để tìm kiếm và tự động lập chỉ mục nội dung trang web và thông tin khác trên internet. Những chương trình này, hay bot, thường được sử dụng để tạo các mục cho một chỉ mục công cụ tìm kiếm.
Web crawler theo dõi các trang web theo cách có hệ thống để hiểu về nội dung của từng trang trên trang web, từ đó thông tin này có thể được lập chỉ mục, cập nhật và truy xuất khi người dùng thực hiện một truy vấn tìm kiếm. Các trang web khác cũng sử dụng bot web crawling khi cập nhật nội dung của họ.
Các công cụ tìm kiếm như Google hoặc Bing áp dụng một thuật toán tìm kiếm cho dữ liệu được thu thập bởi web crawler để hiển thị thông tin và trang web liên quan khi người dùng tìm kiếm.
Nếu một tổ chức hoặc chủ sở hữu trang web muốn trang web của họ được xếp hạng trên một công cụ tìm kiếm, trang web đó phải được lập chỉ mục trước. Nếu các trang web không được crawling và lập chỉ mục, công cụ tìm kiếm không thể tìm thấy chúng theo cách tự nhiên.
Web crawler bắt đầu bằng cách crawling một tập hợp cụ thể các trang web đã biết, sau đó theo dõi các siêu liên kết từ những trang đó đến các trang mới. Các trang web không muốn bị crawling hoặc không muốn xuất hiện trên công cụ tìm kiếm có thể sử dụng các công cụ như tập tin robots.txt để yêu cầu bot không lập chỉ mục trang web hoặc chỉ lập chỉ mục một phần của nó.
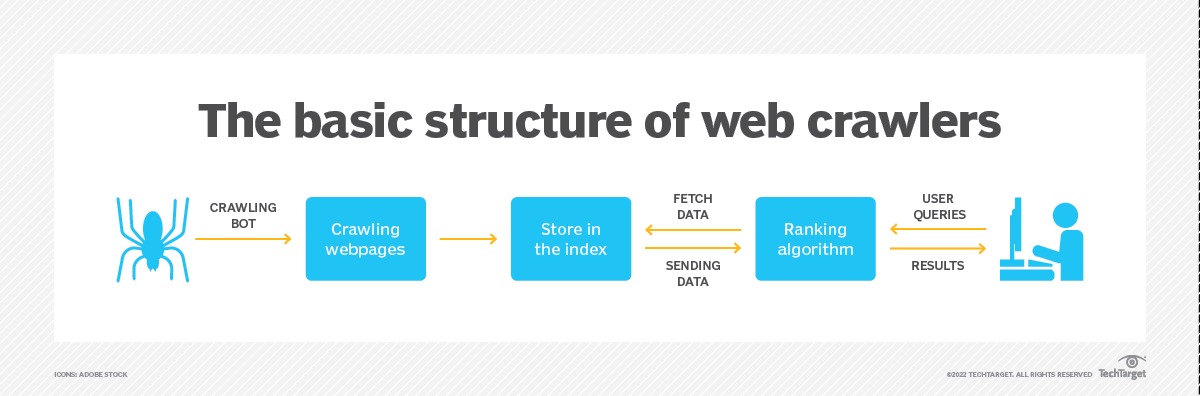
Web crawler hoạt động bằng cách bắt đầu từ một điểm gốc, hoặc danh sách các URL đã biết, xem xét và sau đó phân loại các trang web. Trước khi xem xét mỗi trang, web crawler kiểm tra tập tin robots.txt của trang web, nơi xác định các quy tắc cho bot truy cập trang web. Những quy tắc này xác định trang nào có thể được crawling và các liên kết nào có thể được theo dõi.
Để đến trang web tiếp theo, crawler tìm và theo dõi các siêu liên kết xuất hiện. Liên kết nào mà crawler theo dõi phụ thuộc vào các chính sách đã định nghĩa, làm cho nó trở nên có sự lựa chọn hơn về thứ tự mà crawler nên theo dõi. Ví dụ, các chính sách đã định nghĩa có thể bao gồm các yếu tố sau:
Những yếu tố này cho biết một trang có thể có thông tin quan trọng hơn để lập chỉ mục.
Khi trên một trang web, web crawler lưu trữ bản sao và dữ liệu mô tả được gọi là các thẻ meta, sau đó lập chỉ mục nó để công cụ tìm kiếm quét từ khóa. Quy trình này sau đó quyết định liệu trang có nên xuất hiện trong kết quả tìm kiếm cho một truy vấn hay không, và nếu có, nó trả về một danh sách các trang web được lập chỉ mục theo độ quan trọng.
Trong trường hợp chủ sở hữu trang web không gửi bản đồ trang web của mình để công cụ tìm kiếm crawling trang web, web crawler vẫn có thể tìm thấy trang web bằng cách theo dõi liên kết từ các trang web được lập chỉ mục mà liên kết đến nó.
Hầu hết các công cụ tìm kiếm phổ biến có những web crawler riêng sử dụng một thuật toán cụ thể để thu thập thông tin về các trang web. Công cụ web crawler có thể dựa trên máy tính hoặc dựa trên đám mây. Dưới đây là một số ví dụ về web crawler được sử dụng cho việc lập chỉ mục công cụ tìm kiếm:
Tối ưu hóa công cụ tìm kiếm (SEO) là quá trình cải thiện một trang web để tăng khả năng nhìn thấy của nó khi người ta tìm kiếm sản phẩm hoặc dịch vụ. Nếu một trang web có lỗi làm cho nó khó crawling, hoặc nó không thể crawling, thứ hạng trang của nó trên trang kết quả tìm kiếm của công cụ tìm kiếm (SERP) sẽ thấp hơn hoặc nó sẽ không xuất hiện trong kết quả tìm kiếm tự nhiên. Điều này làm cho quan trọng để đảm bảo các trang web không có liên kết hỏng hoặc lỗi khác và để cho phép bot web crawler truy cập vào trang web và không chặn chúng.
Ngược lại, những trang không được crawling thường xuyên sẽ không phản ánh các thay đổi cập nhật có thể tăng cường SEO. Việc crawling đều đặn và đảm bảo các trang được cập nhật có thể giúp cải thiện SEO, đặc biệt là đối với nội dung mang tính chất thời sự.

Web crawling và web scraping là hai khái niệm tương tự mà có thể dễ dàng gây nhầm lẫn. Sự khác biệt chính giữa chúng là trong khi web crawling liên quan đến việc tìm kiếm và lập chỉ mục các trang web, web scraping liên quan đến việc trích xuất dữ liệu từ một hoặc nhiều trang web.
Web scraping bao gồm việc tạo ra một bot có thể tự động thu thập dữ liệu từ các trang web khác nhau mà không cần sự cho phép. Trong khi web crawlers theo dõi liên kết liên tục dựa trên siêu liên kết, web scraping thường là một quy trình chọn lọc hơn - có thể chỉ quan tâm đến các trang cụ thể.
Trong khi web crawlers tuân thủ tập tin robots.txt, giới hạn yêu cầu để tránh làm quá tải máy chủ web, web scrapers bất kỳ áp lực nào mà chúng có thể gây ra.
Web scraping có thể được sử dụng cho mục đích phân tích - thu thập dữ liệu, lưu trữ và sau đó phân tích nó - để tạo ra các bộ dữ liệu được chọn lọc hơn.
Bots đơn giản có thể được sử dụng trong web scraping, nhưng những bot phức tạp hơn sử dụng trí tuệ nhân tạo để tìm kiếm dữ liệu thích hợp trên một trang và sao chép nó vào trường dữ liệu chính xác để được xử lý bởi ứng dụng phân tích. Các trường hợp sử dụng web scraping dựa trên trí tuệ nhân tạo bao gồm thị trường điện tử, nghiên cứu lao động, phân tích chuỗi cung ứng, thu thập dữ liệu doanh nghiệp và nghiên cứu thị trường.
Các ứng dụng thương mại sử dụng web scraping để thực hiện phân tích cảm xúc về việc ra mắt sản phẩm mới, biên soạn bộ dữ liệu có cấu trúc về công ty và sản phẩm, đơn giản hóa quá trình tích hợp quy trình kinh doanh và dự đoán thu thập dữ liệu.
Như vậy, "crawl" không chỉ là một khái niệm đơn giản trong thế giới web, mà là một quá trình phức tạp đằng sau sự thuận tiện mà chúng ta trải nghiệm mỗi khi tìm kiếm trực tuyến. Chương trình Web Crawler và Web Spider không chỉ là những "nhện" lạ lẫm, mà là những người hùng vô danh làm nền cho sự hiệu quả của công cụ tìm kiếm. Hy vọng rằng, sau khi đọc bài viết này, bạn sẽ có cái nhìn rõ ràng hơn về "crawl là gì" cũng như quy trình quan trọng này và cách nó giúp chúng ta khám phá internet một cách thuận tiện.
Mọi người cùng tìm kiếm: crawl là gì, crawler, web spider, crawl web, web crawling, spider web crawler
Các gói dịch vụ Cloud VPS của KDATA mang đến cho bạn nhiều lựa chọn về hiệu suất cũng như khả năng lưu trữ, mọi nhu cầu về doanh nghiệp đều được đáp ứng. KDATA đảm bảo khả năng uptime lên đến 99,99%, toàn quyền quản trị và free backup hằng ngày. Tham khảo ngay các gói dịch vụ Cloud VPS:
👉 Liên hệ ngay KDATA hỗ trợ tận tình, support tối đa, giúp bạn trải nghiệm dịch vụ giá hời chất lượng tốt nhất
Tips: Tham gia Channel Telegram KDATA để không bỏ sót khuyến mãi hot nào

 English
English









